
Structured Responses
We’re excited to announce that Pyq can now answer queries with structured JSON responses.
Natural language responses are great for a wide variety of uses, but they often lack the ability to be easily processed into databases or to be handled cleanly by subsequent code processes. With our formatted outputs, you can specify the JSON structure that you would like your response to take.
In short, you can do this:
For example, say you’re analyzing a potential customer’s website, and you want to compile a list of their key decision makers for your CRM. With this new feature, it’s just a few lines of code away. Here’s how to do it:
1. Scrape the website: Here’s a simple script that pulls out all of the human readable text from a website and stores it in a txt file. Shoutout to ChatGPT:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin, urlparse
import os
def is_valid(url):
"""
Checks whether `url` is a valid URL.
"""
parsed = urlparse(url)
return bool(parsed.netloc) and bool(parsed.scheme)
def get_all_website_links(url):
"""
Returns all URLs that is found on `url` in which it belongs to the same website
"""
# all URLs of `url`
urls = set()
# domain name of the URL without the protocol
domain_name = urlparse(url).netloc
soup = BeautifulSoup(requests.get(url).content, "html.parser")
for a_tag in soup.findAll("a"):
href = a_tag.attrs.get("href")
if href == "" or href is None:
# href empty tag
continue
# join the URL if it's relative (not absolute link)
href = urljoin(url, href)
parsed_href = urlparse(href)
# remove URL GET parameters, URL fragments, etc.
href = parsed_href.scheme + "://" + parsed_href.netloc + parsed_href.path
if not is_valid(href):
# not a valid URL
continue
if href in urls:
# already in the set
continue
if domain_name not in href:
# external link
continue
urls.add(href)
return urls
def save_text_from_url(url, file):
"""
Saves the human readable text from a URL into a file
"""
soup = BeautifulSoup(requests.get(url).content, "html.parser")
text = soup.get_text(separator='\n')
file.write(text)
def crawl_website(base_url):
"""
Crawls a web site and stores all textual content into a text file.
"""
visited_urls = set()
all_urls = get_all_website_links(base_url)
with open("website_content.txt", "w", encoding="utf-8") as file:
for url in all_urls:
if url not in visited_urls:
print(f"Processing {url}")
try:
save_text_from_url(url, file)
visited_urls.add(url)
except Exception as e:
print(f"Failed to process {url}: {e}")
continue
# Start the crawl from this base URL
base_url = "https://example.com" # Replace with your target URL
crawl_website(base_url)
2. Upload the website text to Pyq: Simply POST the txt file we just created to Pyq’s /create endpoint using the code below
curl --location 'https://document-query.pyqai.com/create' \
--header 'Authorization: ExampleApiToken' \
--form 'account_id="1234"' \
--form 'index_name="a-random-website"' \
--form 'document_source="website"' \
--form 'input_sequence=@"/Documents/website_content.txt"'
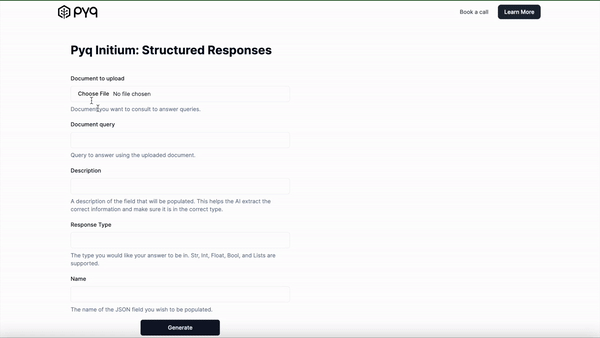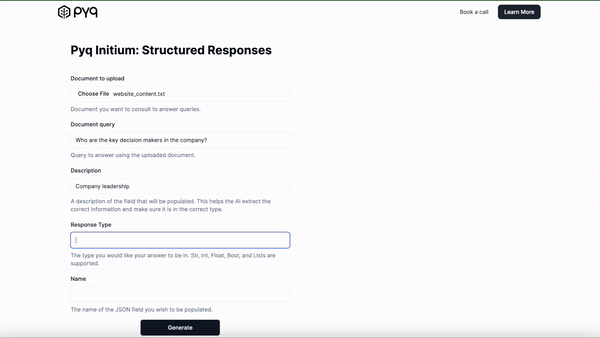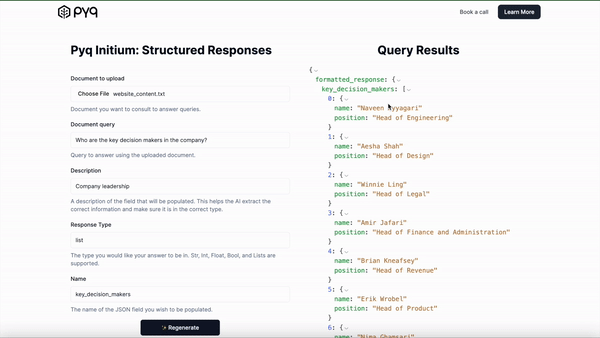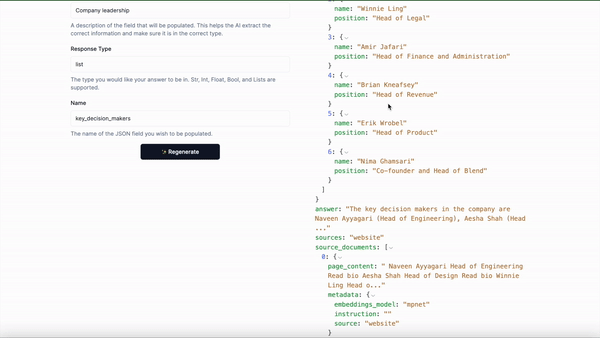
3. Ask away: Our existing /ask endpoint would return something like this: “The key decision makers at Company X’s finance team are: John Smith, Rebecca Brown, Kanishk Kapur, and Hannah Gray.”
While helpful, this cannot be processed easily for input into a database or be passed to another API.
Now, with our new /ask-formatted endpoint, you can specify that you want a return type of list, with the field name “key_decision_makers,” with the description “list of key decision makers in the company.”
The request looks like this:
curl --location 'https://document-query.pyqai.com/ask-formatted?
&account_id=ExampleAccountId
&index_name=random-website
&input_sequence=Who are the key decision makers in the company?
&description=Company leadership
&response_type=list
&name=key_decision_makers
--header 'Authorization: ExampleToken
And the API’s response looks like this:
"key_decision_makers": [
{
"name": "John Smith",
"position": "VP of Engineering"
},
{
"name": "Kelly Brown",
"position": "CEO"
},
{
"name": "Kanishk Kapur",
"position": "CFO"
}]
The above is much easier to process for subsequent use in code, and provides our users with more flexibility over the form that their output takes.
We currently support int, float, bool, str, and list response types - if you require a more complicated JSON output don’t hesitate to reach out to us via the options below and we’ll see how we can help.
Conclusion
Book a call here to learn more and get started! You can also take a look at our technical documentation here.
And if you’d like to follow along with our drop week and receive alerts about all the other new functionality we’re releasing, please fill out your details below!
Drop Week Mailing List

Related posts
Lorem ipsum dolor sit amet, consectetur adipiscing elit.

Blog title heading will go here

Blog title heading will go here
Blog title heading will go here
Stop pushing paper manually
Automate your insurance agency's repetitive tasks by 90% and grow without hiring
Need more help? Email us by clicking here